
AFFINITY PROPAGATION AND K-MEANS ALGORITHM FOR DOCUMENT CLUSTERING BASED ON SEMANTIC SIMILARITY

Article Sidebar
-
Text clustering, semantic similarity, document clustering, Affinity Propagation, K-means, Data mining
Abstract
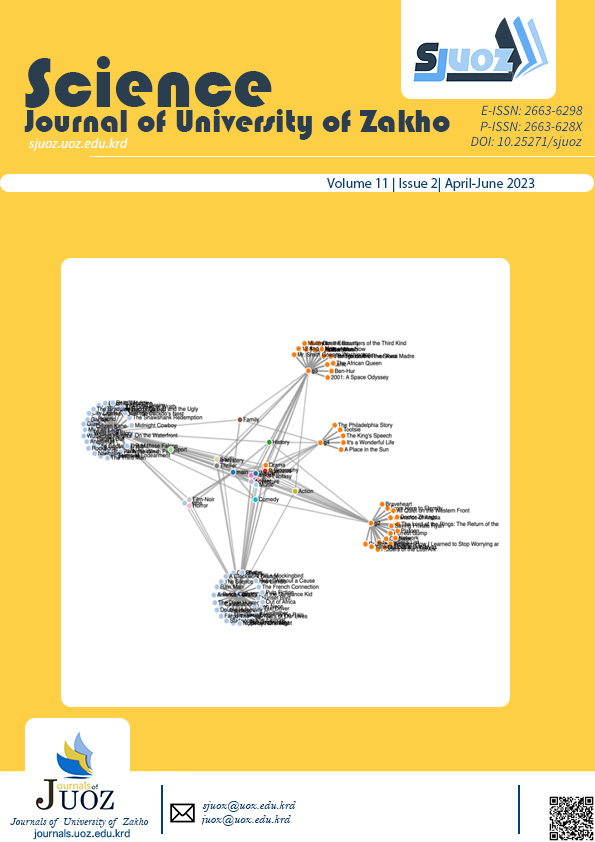
Clustering text documents is the process of dividing textual material into groups or clusters. Due to the large volume of text documents in electronic forms that have been made with the development of internet technology, document clustering has gained considerable attention. Data mining methods for grouping these texts into meaningful clusters are becoming a critical method. Clustering is a branch of data mining that is a blind process used to group data by a similarity known as a cluster. However, the clustering should be based on semantic similarity rather than using syntactic notions, which means the documents should be clustered according to their meaning rather than keywords. This article presents a novel strategy for categorizing articles based on semantic similarity. This is achieved by extracting document descriptions from the IMDB and Wikipedia databases. The vector space is then formed using TFIDF, and clustering is accomplished using the Affinity propagation and K-means methods. The findings are computed and presented on an interactive website.
Full text article
References
K. Jacksi and S. M. Abass, “Development history of the world wide web,” Int. J. Sci. Technol. Res, vol. 8, no. 9, pp. 75–79, 2019.
D. Q. Zeebaree, H. Haron, A. M. Abdulazeez, and S. R. Zeebaree, “Combination of K-means clustering with Genetic Algorithm: A review,” International Journal of Applied Engineering Research, vol. 12, no. 24, pp. 14238–14245, 2017.
K. Jacksi, S. R. M. Zeebaree, and N. Dimililer, “LOD Explorer: Presenting the Web of Data,” International Journal of Advanced Computer Science and Applications, vol. 9, no. 1, 2018.
N. M. Salih and K. Jacksi, “Semantic Document Clustering using K-means algorithm and Ward’s Method,” in 2020 International Conference on Advanced Science and Engineering (ICOASE), 2020, pp. 1–6.
M. B. Revanasiddappa, B. S. Harish, and S. v Aruna Kumar, “Clustering text documents using kernel possibilistic C-means,” in Proceedings of International Conference on Cognition and Recognition, 2018, pp. 127–134.
M. Allahyari et al., “A brief survey of text mining: Classification, clustering and extraction techniques,” arXiv preprint arXiv:1707.02919, 2017.
D. Chandrasekaran and V. Mago, “Evolution of semantic similarity—a survey,” ACM Computing Surveys (CSUR), vol. 54, no. 2, pp. 1–37, 2021.
R. Ibrahim, S. Zeebaree, and K. Jacksi, “Survey on semantic similarity based on document clustering,” Adv. sci. technol. eng. syst. j, vol. 4, no. 5, pp. 115–122, 2019.
N. M. Salih and K. Jacksi, “State of the art document clustering algorithms based on semantic similarity,” J. Inform, vol. 14, no. 2, pp. 58–75, 2020.
P. Bafna, D. Pramod, and A. Vaidya, “Document clustering: TF-IDF approach,” in 2016 International Conference on Electrical, Electronics, and Optimization Techniques (ICEEOT), 2016, pp. 61–66.
R. Guan, X. Shi, M. Marchese, C. Yang, and Y. Liang, “Text clustering with seeds affinity propagation,” IEEE Transactions on Knowledge and Data Engineering, vol. 23, no. 4, pp. 627–637, 2010.
K. Jacksi, R. K. Ibrahim, S. R. M. Zeebaree, R. R. Zebari, and M. A. M. Sadeeq, “Clustering documents based on semantic similarity using HAC and K-mean algorithms,” in 2020 International Conference on Advanced Science and Engineering (ICOASE), 2020, pp. 205–210.
S. M. Mohammed, K. Jacksi, and S. R. M. Zeebaree, “Glove word embedding and DBSCAN algorithms for semantic document clustering,” in 2020 International Conference on Advanced Science and Engineering (ICOASE), 2020, pp. 1–6.
B. K. Triwijoyo and K. Kartarina, “Analysis of Document Clustering based on Cosine Similarity and K-Main Algorithms,” Journal of Information Systems and Informatics, vol. 1, no. 2, pp. 164–177, 2019.
R. N. Rathi and A. Mustafi, “The importance of Term Weighting in semantic understanding of text: A review of techniques,” Multimedia Tools and Applications, pp. 1–23, 2022.
A. M. Serdah and W. M. Ashour, “Clustering large-scale data based on modified affinity propagation algorithm,” Journal of Artificial Intelligence and Soft Computing Research, vol. 6, no. 1, pp. 23–33, 2016.
D. Dueck and B. J. Frey, “Non-metric affinity propagation for unsupervised image categorization,” in 2007 IEEE 11th International Conference on Computer Vision, 2007, pp. 1–8.
K. P. Sinaga and M.-S. Yang, “Unsupervised K-means clustering algorithm,” IEEE access, vol. 8, pp. 80716–80727, 2020.
P. J. Rousseeuw, “Silhouettes: a graphical aid to the interpretation and validation of cluster analysis,” J Comput Appl Math, vol. 20, pp. 53–65, 1987.
C. D. ; R. P. ; S. H. Manning, “Chapter 1: Boolean Retrieval,” in Introduction to information retrieval,
P. Huilgol, “Accuracy vs. F1-score,” medium. com/analytics-vidhya/accuracy-vs-f1-score-6258237beca2, 2019.
S. Morbieu, “Accuracy: from classification to clustering evaluation (2019),” URL https://smorbieu. gitlab. io/accuracy-from-classification-to-clustering-evaluation/#:~: text= Computing% 20accuracy% 20for% 20clustering% 20can, the% 20accuracy% 20for% 20clustering% 20results.
Authors
Copyright (c) 2023 Avan A. Mustafa, Karwan Jacksi

This work is licensed under a Creative Commons Attribution 4.0 International License.
Authors who publish with this journal agree to the following terms:
- Authors retain copyright and grant the journal right of first publication with the work simultaneously licensed under a Creative Commons Attribution License [CC BY-NC-SA 4.0] that allows others to share the work with an acknowledgment of the work's authorship and initial publication in this journal.
- Authors are able to enter into separate, additional contractual arrangements for the non-exclusive distribution of the journal's published version of the work, with an acknowledgment of its initial publication in this journal.
- Authors are permitted and encouraged to post their work online.