
AN IMPROVED DEEP LEARNING TECHNIQUE FOR SPEECH EMOTION RECOGNITION AMONG HAUSA SPEAKERS

Article Sidebar
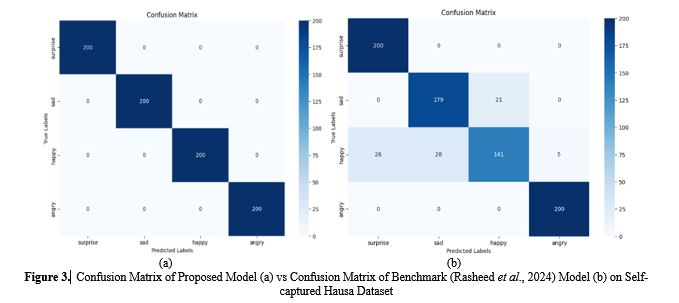
-
Emotion Recognition, Hausa Audio Data, Bi-Directional Long-Term Short-Term Memory Network, BILSTM, Cross-Cultural Variations
Abstract
This research addressed the challenge of recognizing emotions from speech by developing a deep learning-based speech-emotion recognition (SER) system. A key focus of the study is the creation of a new Hausa emotional speech dataset, aimed at addressing the linguistic and cultural imbalance in existing SER datasets, which predominantly feature Western languages. This study captured four emotions: happy, sad, angry, and surprise among native Hausa speakers. The self-captured dataset was recorded in an environment that is devoid of noise to ensure high quality and uniformity in the audio data. A public dataset; RAVDESS was used for benchmarking the proposed technique. CNN and Bi-Directional Long Short-Term Memory (BiLSTM) architectures were combined and used as proposed model for the SER experiment. The developed CNN architecture helped in extracting spatial features, while the BiLSTM without the attention mechanism captured temporal dependencies from the audio data. The approach reduced time complexity and improved performance to 100% and 96% recognition accuracies against 94% and 90% of the benchmark model for the local and benchmark datasets respectively. The results demonstrate the proposed approach's robustness to generalize across linguistic contexts.
Full text article
References
REFERENCES
Abbaschian, B. J., Sierra-Sosa, D., & Elmaghraby, A. (2021). Deep Learning Techniques for Speech Emotion Recognition, from Databases to Models. Sensor Journal, 4(21), 1249. https://doi.org/https://doi.org/10.3390/s21041249
Ahmed, S. A., Mahmood, B. N., Mahmood, D. J., & Namq, M. M. (2024). ENHANCING KURDISH SIGN LANGUAGE RECOGNITION THROUGH RANDOM FOREST CLASSIFIER AND NOISE REDUCTION VIA SINGULAR VALUE DECOMPOSITION (SVD). Science Journal of University of Zakho, 12(2), 257-267. https://doi.org/10.25271/sjuoz.2024.12.2.1263
Al-Tamimi, J. (2022). JalalAl-Tamimi/Praat-Silence-Detection: Praat-Silence detection. In Zenodo.
Ali, S. H., Mohammed, A. I., Mustafa, S. M. A., & Salih, S. O. (2025). WEB VULNERABILITIES DETECTION USING A HYBRID MODEL OF CNN, GRU AND ATTENTION MECHANISM. Science Journal of University of Zakho, 13(1), 58-64. https://doi.org/10.25271/sjuoz.2025.13.1.1404
Barazida, N. (2021). 40 Open-Source Audio Datasets for ML. In: Towards Data Science.
Calzone, O. (2022). An Intuitive Explanation of LSTM. An Intuitive Explanation of LSTM.
Dixit, C., & Satapathy, S. M. (2023). Deep CNN with late fusion for real time multimodal emotion recognition. Expert Systems with Applications, 240, 122579. https://doi.org/10.1016/j.eswa.2023.122579
Duttaa, D., Halderb, S., & Gayen, T. (2023). Intelligent Part of Speech tagger for Hindi. Procedia Computer Science, 218(3), 604-611.
Elbanna, G., Scheidwasser-Clow, N., Kegler, M., Beckmann, P., Hajal, K. E., & Cernak, M. (2021). BYOL-S: Learning Self-supervised Speech Representations by Bootstrapping. Proceedings of Machine Learning Research, 86(6), 365-375. https://doi.org/arXiv:2206.12038v4 [cs.SD]
Goncalves, L., Leem, S.-G., Lin, W.-C., Sisman, B., & Busso, C. (2023). VERSATILE AUDIO-VISUAL LEARNING FOR HANDLING SINGLE AND MULTI MODALITIES IN EMOTION REGRESSION AND CLASSIFICATION TASKS. Prime AI, 18(2), 5587-5598.
Gong, Y., Chung, Y.-A., & Glass, J. (2021). Audio Spectrogram Transformer. MIT Computer Science and Artificial Intelligence Laboratory, Cambridge, MA 02139, USA, 23(3), 524-577. https://doi.org/arXiv:2104.01778v3 [cs.SD]
Harár, P., Burget, R., & Dutta, M. K. (2016). Emotion recognition using MFCC and RBF network. International Journal of Engineering and Technology, 8(1), 209-315. https://doi.org/10.21817/ijet/2016/v8i1/160801309
Hasan, Z. F. (2022). An Improved Facial Expression Recognition Method Using Combined Hog and Gabor Features. Science Journal of University of Zakho, 10(2), 54-59. https://doi.org/10.25271/sjuoz.2022.10.2.897
Hassan, D. A. (2025). DEEP NEURAL NETWORK-BASED APPROACH FOR COMPUTING SINGULAR VALUES OF MATRICES. Science Journal of University of Zakho, 13(1), 1-6. https://doi.org/10.25271/sjuoz.2025.13.1.1345
Hassan, M. M., & Ahmed, D. (2023). BAYESIAN DEEP LEARNING APPLIED TO LSTM MODELS FOR PREDICTING COVID-19 CONFIRMED CASES IN IRAQ. Science Journal of University of Zakho, 11(2), 170-178. https://doi.org/10.25271/sjuoz.2023.11.2.1037
Hossain, M. S., & Muhammad, G. (2018). Deep learning approach for emotion recognition from audio-visual data. Personal and Ubiquitous Computing, 22(1), 3-14. https://doi.org/https://doi.org/10.1007/s00779-017-1072-7
Ibrahim, U. A. (2021). Hausa Speech Dataset. Mendley Data, 23(1). https://doi.org/10.17632/z38hsttxb.1
Irhebhude, M. E., Kolawole, A., & Goshit, N. (2023). Perspective on Dark-Skinned Emotion Recognition Using Deep-Learned and Handcrafted Feature Techniques. Emotion Recognition Using Deep-Learned and Handcrafted Feature Techniques, 2(5), 25-50. https://doi.org/10.5772/intechopen.109739
Irhebhude, M. E., Kolawole, A. O., & Zubair, W. M. (2024). Sign Language Recognition Using Residual Network Architectures for Alphabet And Diagraph Classification. Journal of Computing and Social Informatics, 4(1), 11-25. https://doi.org/10.33736/jcsi.7986.2025
Jeong, E., Kim, G., & Kang, S. (2023). Multimodal Prompt Learning in Emotion Recognition Using Context and Audio Information. Mathematics Journal, 11(2), 2908-2923. https://doi.org/https://doi.org/ 10.3390/math11132908
Kim, Y., Lee, H., Provost, & Mower, E. (2015). Deep learning approaches for emotion recognition from speech and non-speech. Proceedings of the 2015 ACM on International Conference on Multimodal Interaction, 25(2), 433-440. https://doi.org/https://doi.org/10.1145/2818346.2820779
Middya, A. I., Nag, B., & Roy, S. (2022). Deep learning based multimodal emotion recognition using model-level fusion of audio–visual modalities. Knowledge-Based Systems, 244, 108580. https://doi.org/10.1016/j.knosys.2022.108580
Njoku, J. N., Caliwag, A. C., Lim, W., Kim, S., Kim, S., Hwang, H.-J., & Jeong, J.-W. (2021). Deep Learning Based Data Fusion Methods for Multimodal Emotion Recognition. The Journal of Korean Institute of Communications and Information Sciences, 47(1), 79-122.
Rasheed, B. H., Yuvaraj, D., Alnuaimi, S. S., & Priya, S. S. (2024). Automatic Speech Emotion Recognition Using Hybrid Deep Learning Techniques. International Journal of INTELLIGENT SYSTEMS AND APPLICATIONS IN ENGINEERING, 12(15), 87-96.
SaiDhruv, Y. H., k, P., & Vardhan, M. V. (2023). Speech Emotion Recognition Using LSTM Model. International Conference on Recent Trends in Data Science and its Applications, 5(4), 692-697. https://doi.org/rp-9788770040723.133
Saunders, M. (2023). Hausa. Oxford University Press, London.
Schonevelda, L., Othmanib, A., & Abdelkawyb, H. (2020). Leveraging Recent Advances in Deep Learning for Audio-Visual Emotion Recognition: A Review of Recent Progress. Signal Processing Magazine, 37(5), 141-152. https://doi.org/10.1109/MSP.2020.3006019
Selvaraj, M., Bhuvana, R., & Padmaja, S. (2016). Recognising emotions using deep learning. International Journal of Engineering and Technology, 8(1). https://doi.org/10.21817/ijet/2016/v8i1/160801309
Singh, P., Srivastava, R., Rana, K. P. S., & Kumar, V. (2021). A multimodal hierarchical approach to speech emotion recognition from audio and text. Knowledge-Based Systems, 229, 107316. https://doi.org/10.1016/j.knosys.2021.107316
Sundar, B. S., Rohith, V., Suman, B., & Chary, K. N. (2022). Emotion Detection in Text Using Machine Learning and Deep Learning Techniques. International Journal for Research in Applied Science & Engineering Technology, 10(6), 2276-2282. https://doi.org/https://doi.org/10.22214/ijraset.2022.44293
Tarunika, K., Pradeeba, R. B., & Aruna, P. (2018). Accuracy of speech emotion recognition through deep neural network and k-nearest. International Journal of Engineering Research in Computer Science and Engineering,, 5(2), 2320-2394.
Tzirakis, P., Trigeorgis, G., Nicolaou, M. A., Schuller, B., & Zafeiriou, S. (2017). Automatic recognition of emotion in speech and facial expressions: A multimodal approach. IEEE Transactions on Affective Computing, 9(4), 578-584.
Vaaras, E., Ahlqvist-Björkroth, S., Drossos, K., Lehtonen, L., & Räsänen, O. (2023). Development of a speech emotion recognizer for large-scale child-centered audio recordings from a hospital environment. Speech Communication, 148, 9-22. https://doi.org/10.1016/j.specom.2023.02.001
Zaman, K., Sah, M., Direkoglu, C., & Unoki, M. (2023). A Survey of Audio Classification Using Deep Learning. IEEE ACCESS, 10(7), 290-350. https://doi.org/10.1109/ACCESS.2023.3318015
Zhou, S., & Beigi, H. (2020). A Transfer Learning Method for Speech Emotion Recognition from Automatic Speech Recognition. Electrical Engineering and Systems Science, 5(7), 2356-2363. https://doi.org/arXiv: 2008.02863v2
Authors
Copyright (c) 2025 Martins E Irhebhude, Adeola O Kolawole, Mujtaba K Tahi

This work is licensed under a Creative Commons Attribution 4.0 International License.
Authors who publish with this journal agree to the following terms:
- Authors retain copyright and grant the journal right of first publication with the work simultaneously licensed under a Creative Commons Attribution License [CC BY-NC-SA 4.0] that allows others to share the work with an acknowledgment of the work's authorship and initial publication in this journal.
- Authors are able to enter into separate, additional contractual arrangements for the non-exclusive distribution of the journal's published version of the work, with an acknowledgment of its initial publication in this journal.
- Authors are permitted and encouraged to post their work online.